![[Image (JPEG): Laxmi Pandey]](lax1.jpg) |
Laxmi PandeyResearch Scientist |
I am a Research Scientist at Meta AI, where I work with the Speech team. My research is interdisciplinary, encompassing various fields such as audio-visual speech recognition, natural language processing, human-computer interaction, and applied artificial intelligence. Prior to joining Meta AI, I pursued my doctoral studies as a fellow at the University of California, Merced, under the guidance of Prof. Ahmed Sabbir Arif. During my PhD, my research garnered recognition through several prestigious awards, including the Fred and Mitzie Ruiz Fellowship, the Hatano Cognitive Development Research Fellowship, the ACM-W Scholarship, and the SIGIR Travel Grant. Additionally, I hold a Master's degree from the Indian Institute of Technology Kanpur, India, where I worked with Prof. Rajesh M Hegde. Over the course of my research, my work has been featured in numerous national and international media outlets, resulting in 21 publications.
Publications

Minh Tran, Yutong Pang, Debjyoti Paul, Laxmi Pandey, Kevin Jiang, Jinxi Guo, Ke Li, Shun Zhang, Xuedong Zhang, Xin Lei
In review
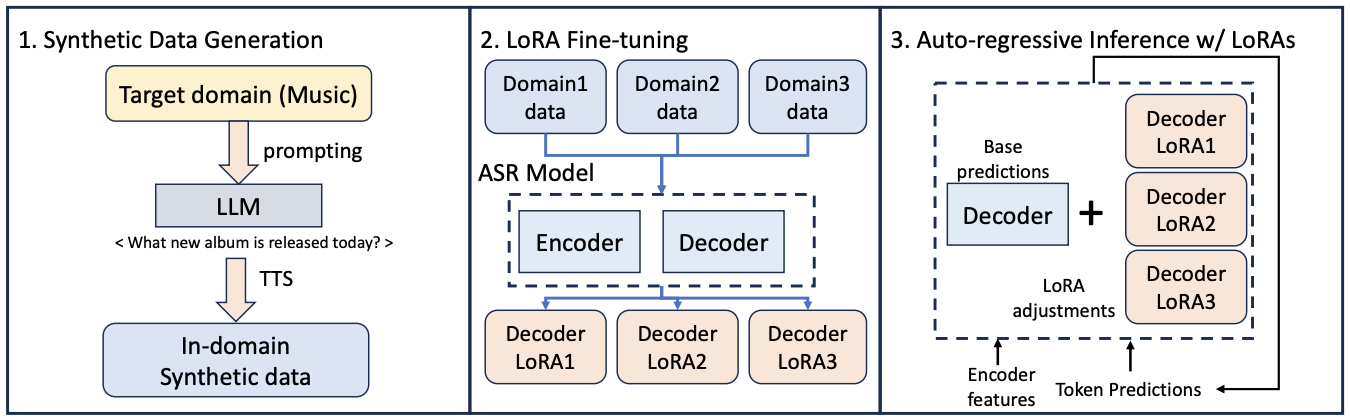
Minh Tran, Yutong Pang, Debjyoti Paul, Laxmi Pandey, Kevin Jiang, Jinxi Guo, Ke Li, Shun Zhang, Xuedong Zhang, Xin Lei
IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025
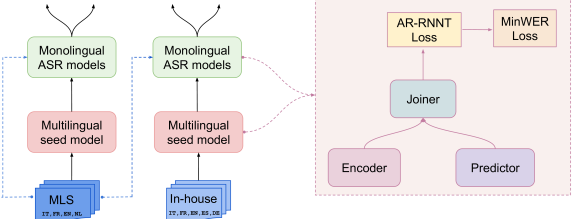
Laxmi Pandey, Ke Li, Jinxi Guo, Debjyoti Paul, Arthur Guo, Jay Mahadeokar, Xuedong Zhang
arXiv preprint arXiv:2407.16664, 2024

Laxmi Pandey, Ahmed Sabbir Arif
CHI Conference on Human Factors in Computing Systems, CHI 2024
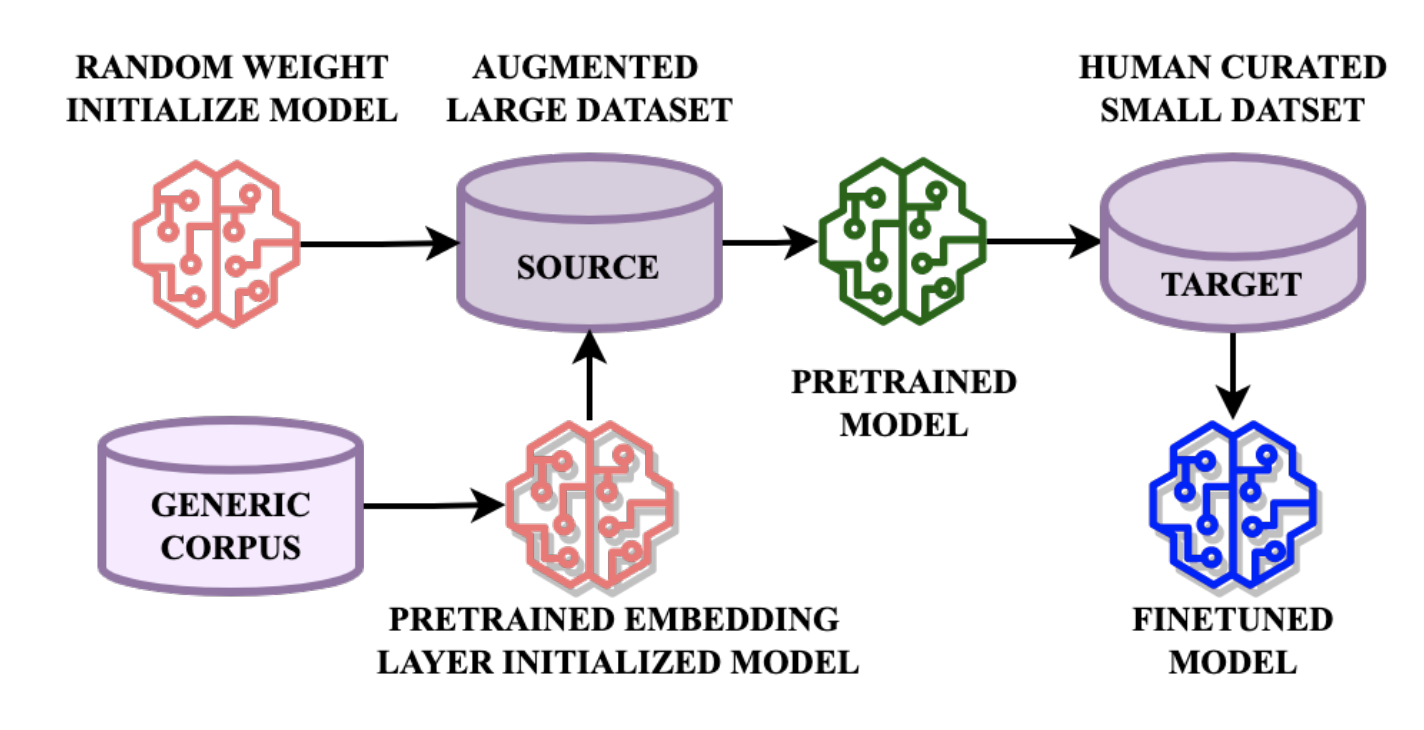
Laxmi Pandey, Debjyoti Paul, Pooja Chitkara, Yutong Pang, Xuedong Zhang, Kjell Schubert, Mark Chou, Shu Liu, Yatharth Saraf
arXiv preprint arXiv:2207.09674, 2022

Laxmi Pandey, Ahmed Sabbir Arif
ACM Interactive Surfaces and Spaces Conference, ISS 2022

Laxmi Pandey, Ahmed Sabbir Arif
Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems, CHI EA 2022
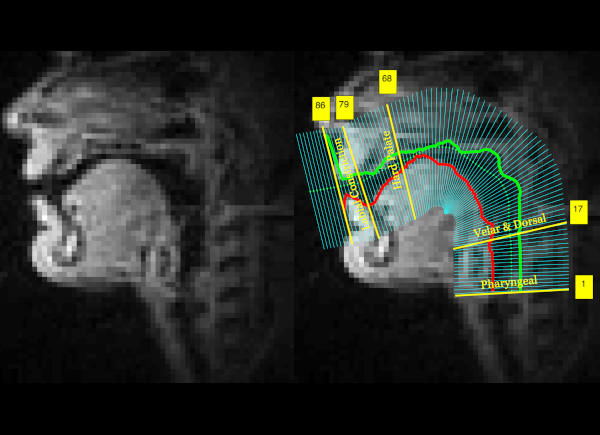
Laxmi Pandey, Ahmed Sabbir Arif
Special Interest Group on Computer Graphics and Interactive Techniques Conference Posters, SIGGRAPH 2021 [Poster]
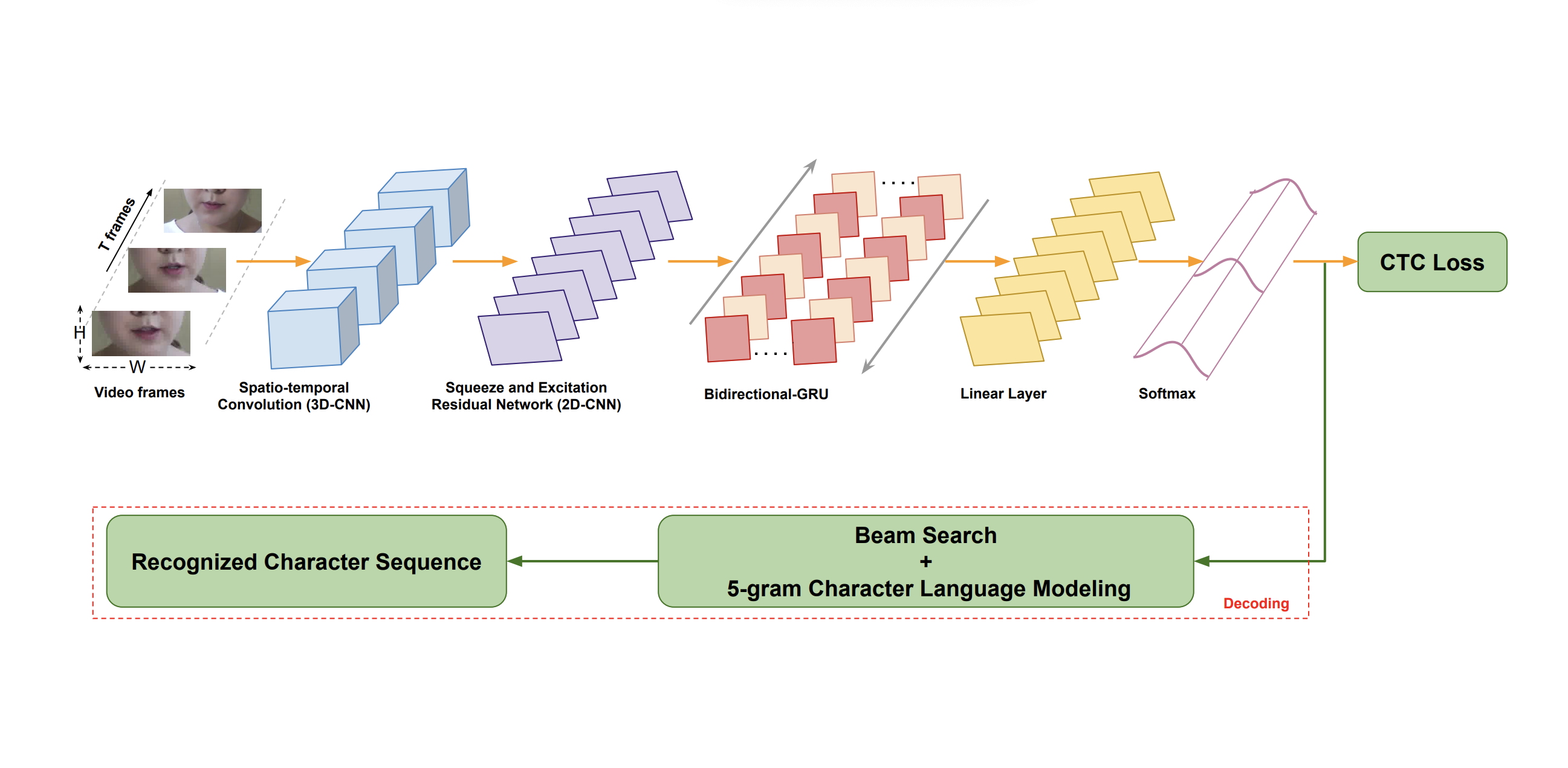
Laxmi Pandey, Ahmed Sabbir Arif
CHI Conference on Human Factors in Computing Systems, CHI 2021

Laxmi Pandey, Khalad Hasan, Ahmed Sabbir Arif
CHI Conference on Human Factors in Computing Systems, CHI 2021
Laxmi Pandey, Ahmed Sabbir Arif
IEEE International Conference on Systems, Man, and Cybernetics, SMC 2020

Laxmi Pandey, Ahmed Sabbir Arif
ACM Conference on Human Information Interaction and Retrieval, CHIIR 2020
Steven J. Castellucci, I. Scott MacKenzie, Mudit Misra, Laxmi Pandey, Ahmed Sabbir Arif
ACM International Conference on Mobile and Ubiquitous Multimedia, MUM 2019
Laxmi Pandey, Ahmed Sabbir Arif
ACM International Conference on Mobile and Ubiquitous Multimedia, MUM 2019 [Poster]
Aditya Raikar , Saurya Basu, Laxmi Pandey, Rajesh M. Hegde
IEEE India Council International Conference, INDICON 2018
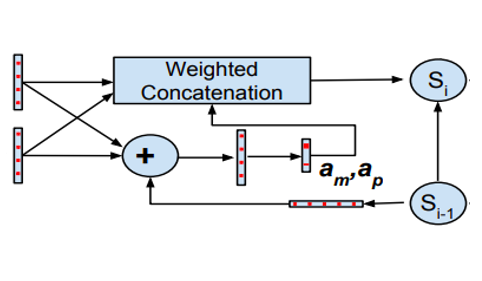
Laxmi Pandey, Karan Nathwani
Interspeech 2018
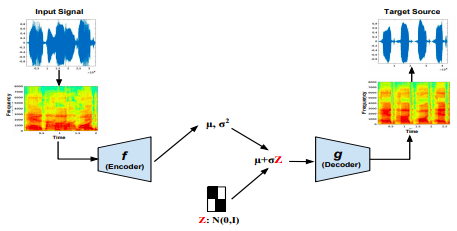
Laxmi Pandey, Anurendra Kumar, Vinay Namboodiri
Interspeech 2018
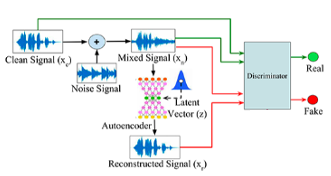
Laxmi Pandey, Nitish Divakar, Krishna D N, Anuroop Iyengar
NVIDIA’s GPU Technology Conference, GTC 2018 [Poster]
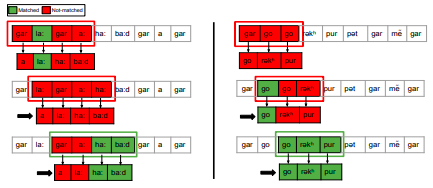
Laxmi Pandey, Rajesh M. Hegde
Circuits Systems and Signal Processing, CSSP Springer, 2018 [Journal]
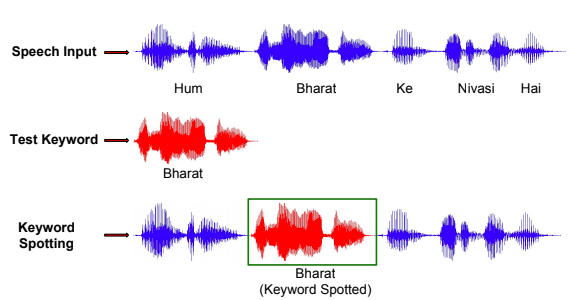
Laxmi Pandey, Kuldeep Chaudhary, Rajesh M. Hegde
IEEE National Conference on Communications, NCC 2017
L. Pandey, K. Nathwani, S. Kaur, I. Hussain, R. Pathak, G. Singh, S. Tiwari, Rajesh M. Hegde
IEEE Symposium on Signal Processing and Information Technology, ISSPIT 2014